
 por
por Determinar las coberturas de la tierra para la acuicultura, implica el análisis de las mismas utilizando técnicas de Sistemas de Información Geográfica (SIG).
Este análisis se centra en clasificar y mapear las diferentes coberturas de la tierra en el área de interés, lo que incluye identificar áreas con características adecuadas para la acuicultura, como cuerpos de agua, tierras agrícolas y zonas con acceso a infraestructuras relevantes.
El análisis de cobertura de la tierra puede implicar la utilización de técnicas de clasificación de imágenes, tanto supervisadas como no supervisadas, para diferenciar y categorizar las diversas coberturas presentes en la región de interés. Estas técnicas permiten identificar áreas de agua dulce, como lagos, ríos o estanques, que son fundamentales para la acuicultura, así como tierras agrícolas que podrían ser adecuadas para la construcción de estanques o para la producción de alimentos para peces.
En este artículo, se va a realizar una clasificación de coberturas, mediante las dos metodologías: CLASIFICACIÓN SUPERVISADA Y CLASIFICACIÓN NO SUPERVISADA, teniendo como zona de estudio: La Represa de Betania, localizada en el departamento del Huila, es un embalse de grandes proporciones construido en la desembocadura del río Yaguará en el Magdalena, en los municipios de Campoalegre, Hobo y Yaguará (Colombia).
Empecemos!
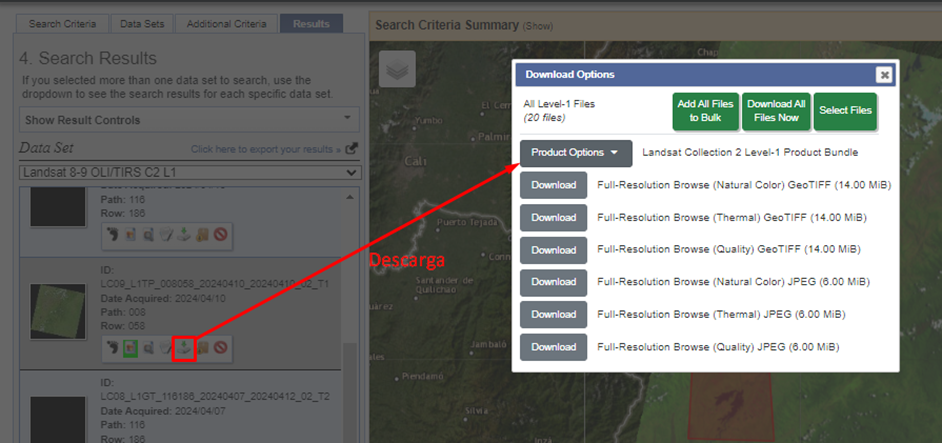
- Descarga una imagen del satélite landsat, de la página: https://earthexplorer.usgs.gov/, recuerda crear una cuenta primero.
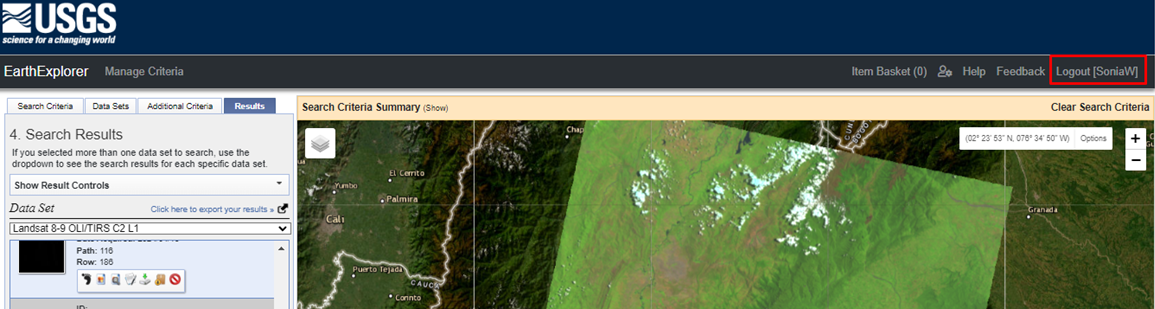
2. Selecciona el área de interés, dando clic encima de la zona de estudio, además elige la fecha.

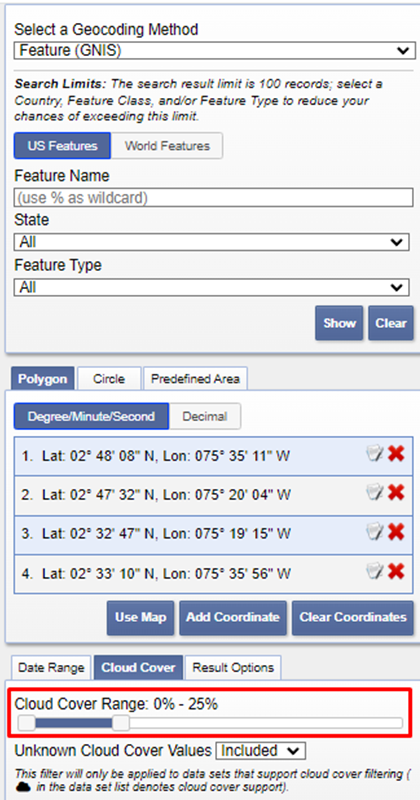
3. Selecciona una cobertura de nubes en un rango de menos del 50%. Nota: La nubosidad puede generar error en la clasificación, siempre realiza una clasificación con ausencia de nubes en el área específica.
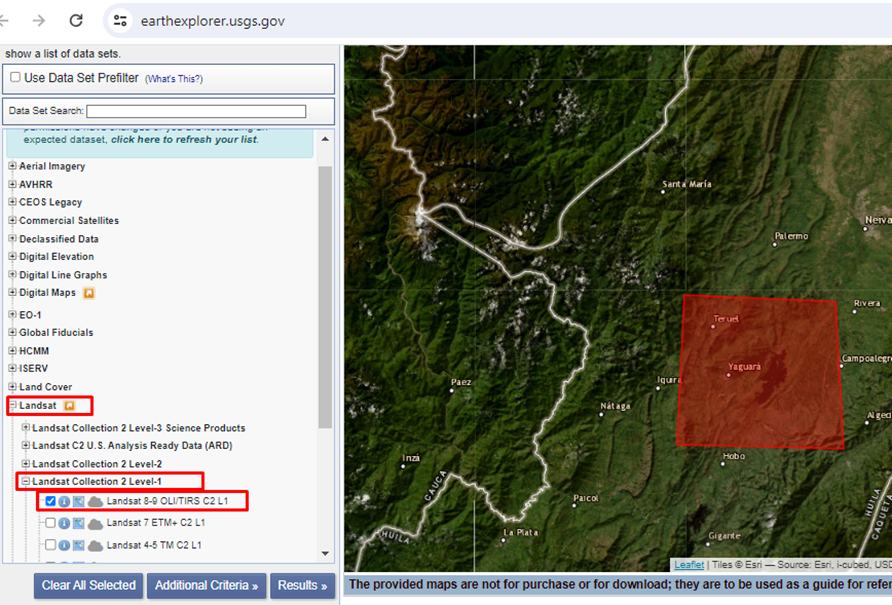
4. Para este caso se eligió la colección 2 level 1, en este nivel, los datos de la imágenes son almacenados en números digitales (DN), que se pueden convertir a reflectancia en la parte superior de la atmósfera o radiancia en el sensor utilizando los metadatos (paso que verá más adelante) proporcionados junto con el producto, mientras que el producto colección 2 level 2, son los datos de imagen calculados en función del producto de nivel 1.
5. Se puede realizar una previsualización.
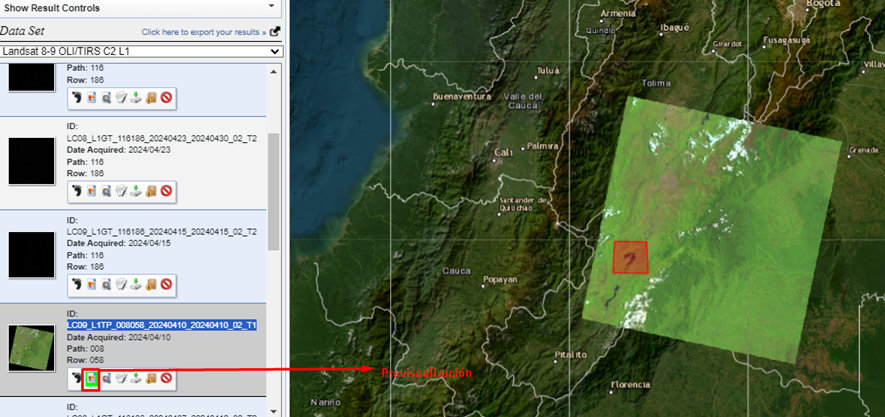
- Nota: las abreviaturas de la imagen satelital significan lo siguiente:
- LXSS_LLLL_PPPRRR_YYYYMMDD_yyymmdd_CC_TX
- L: Landsat
- X: Sensor de captura de la imagen. Encontrarás una letra o grupo de letras para identificar el sensor que tomó la imagen. Estos sensores serán C (OLI/TIRS), O (OLI), T (TIRS), E (ETM+), T (TM) y M (MSS)
- SS: Generación del satellite, por ejemplo, Landsat 8
- LLLL: Nivel de procesado de la imagen según su corrección geométrica y geométrica pudiendo encontrar L1TP, L1GT o L1GS
- L1TP: L1TP (Corregida de Precisión y Terreno Nivel 1): Este es el nivel más alto de corrección geométrica que se ofrece para las imágenes Landsat.
- L1GT (Corregida Sistemática de Terreno Nivel 1): Este nivel de corrección aplica correcciones sistemáticas para tener en cuenta la distorsión del terreno causada por el ángulo de visión del satélite. Utiliza un Modelo Digital de Elevación (DEM) para ajustar la elevación de las características en la imagen. Si bien no es tan precisa como L1TP
- L1GS (Corregida Sistemáticamente Nivel 1): Este es el nivel más básico de corrección geométrica.
- PPP: Path
- RRR: Row
- YYYYMMDD: Fecha de adquisición de la imagen en formato año/mes/día
- yyyymmdd: Fecha de procesado de la imagen en formato año/mes/día
- CC: Número de colección
- TX: Categoría de la colección, pudiendo encontrar nomenclaturas de RT (Real Time), T1 (Tier 1) o T2 (Tier 2). Los archivos Tier 1 presentan corrección en la precisión y radiometría. Los archivos Tier 2 no presentan correcciones en la geometría debido a la imprecisión de la órbita.
- Descarga la imagen.
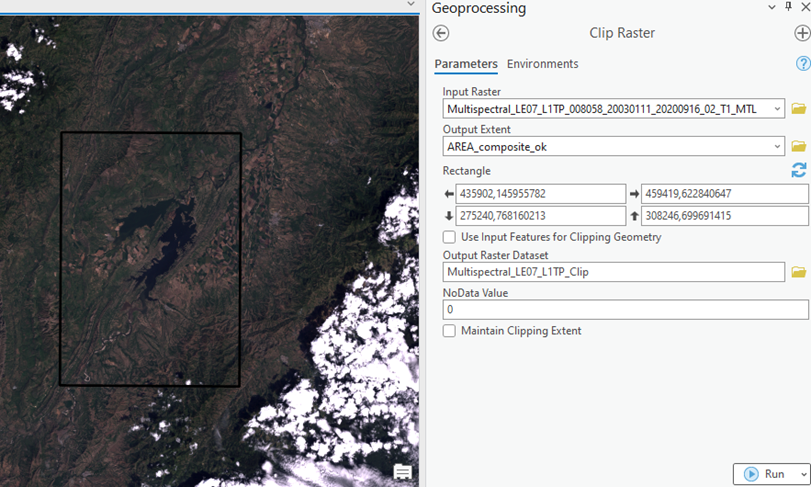
7. Dentro de ArcGis pro, se realizará un recorte con la herramienta Clip raster, esto con el fin de emplear menos memoria en el ordenador. El clip será del archivo MTL.
8. Se realiza una corrección de reflectancia aparente, para esto: Imagery > Raster Functions > Correction > Apparent Reflectance.
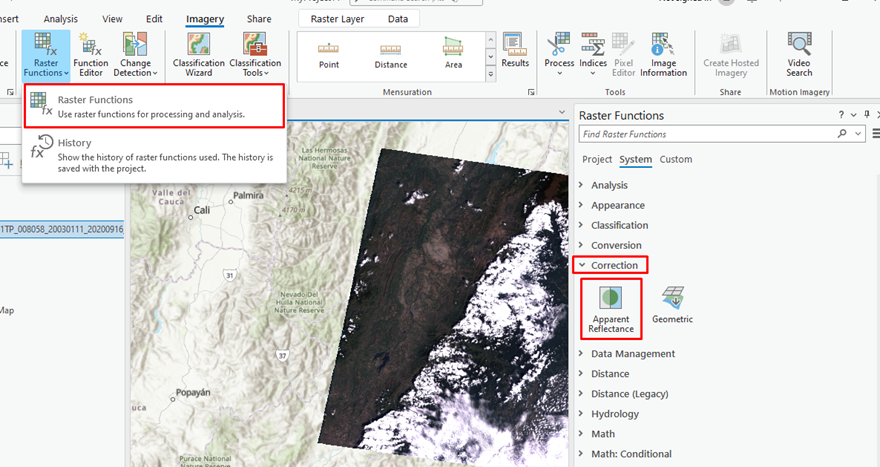
9.Ingresar el Clip previamente realizado.

Nota: Seleccionar la opción del Albedo.
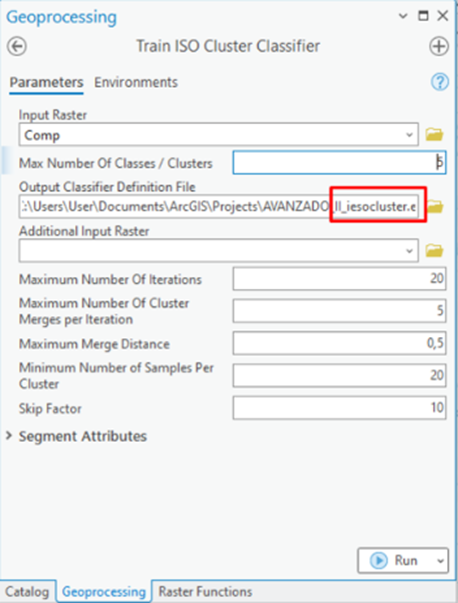
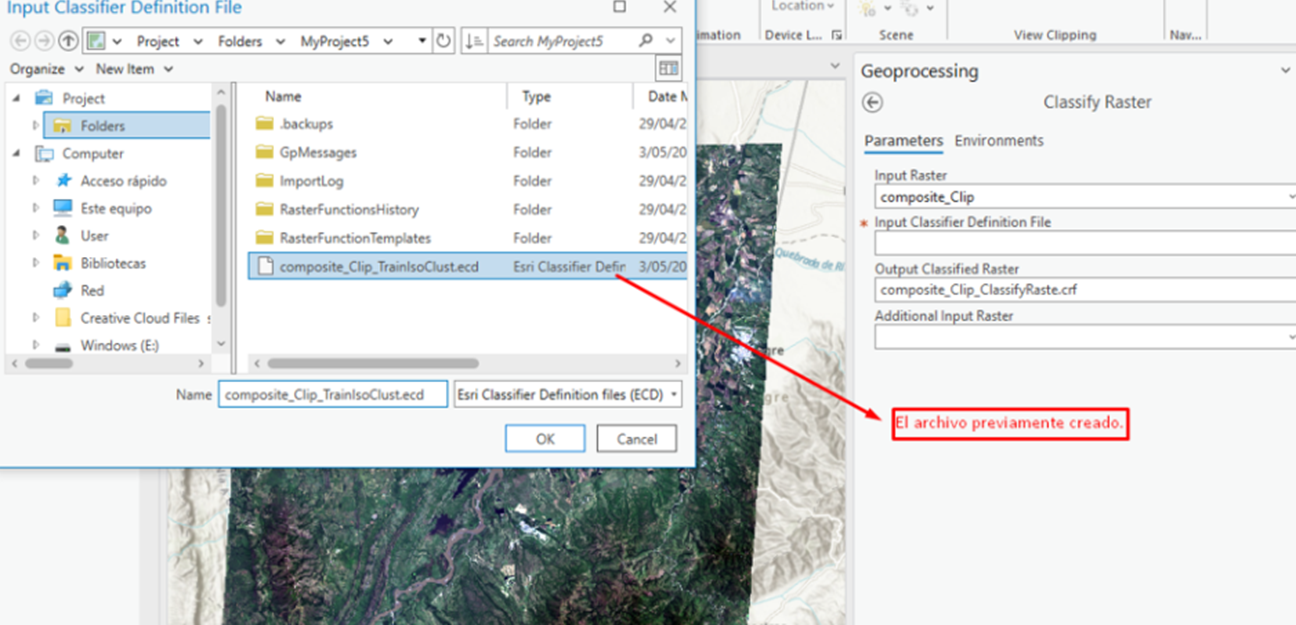
- Para realizar la clasificación NO SUPERVISADA, se busca la herramienta Train ISO cluster Classifier, el cual genera una salida .ECD, en Máx Number of classes/Cluster: Se coloca un número apróx de clases de cobertura que el investigador considere, dependiendo de la zona.
11. Emplear la herramienta classify raster
En el Input Raster: Colocar el archivo.tif que se genero después de la corrección de reflectancia aparente.
En el Input classififer Definition File: El archivo previamente generado ECD.
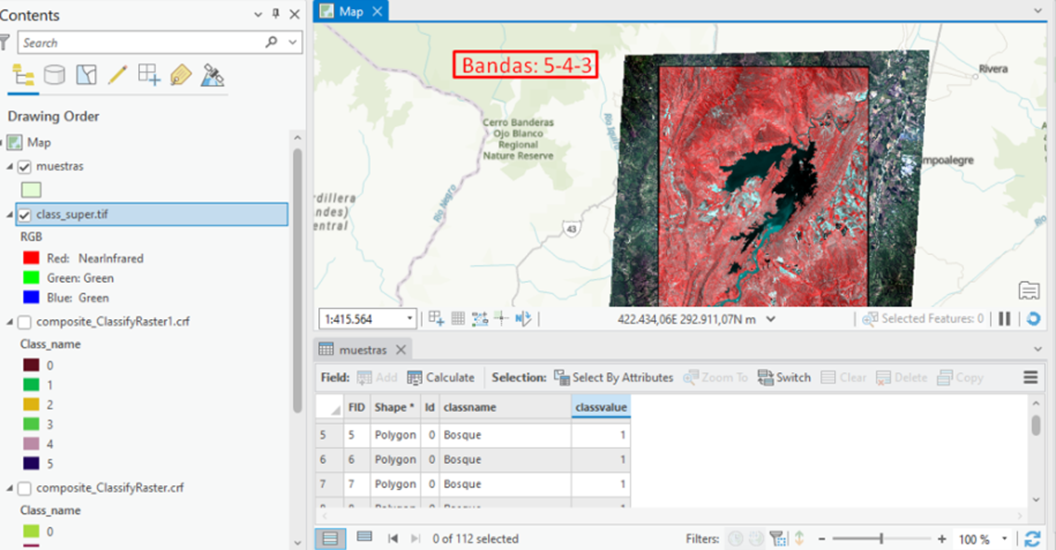
12. Para realizar la clasificación supervisada, se crea un archivo .shp, en la tabla de atributos se crea dos columnas de tipo texto“classname” y “classvalue” , las cuales permitiran tomar muestras de cada cobertura, como mínimo generar 30, es decir, si hay dos cobertura, en total deben haber 60 muestras, por lo general, esto se hace en campo empleando un GPS, además es posible emplear combinaciones de bandas, las cuales permitirán una previsualización.
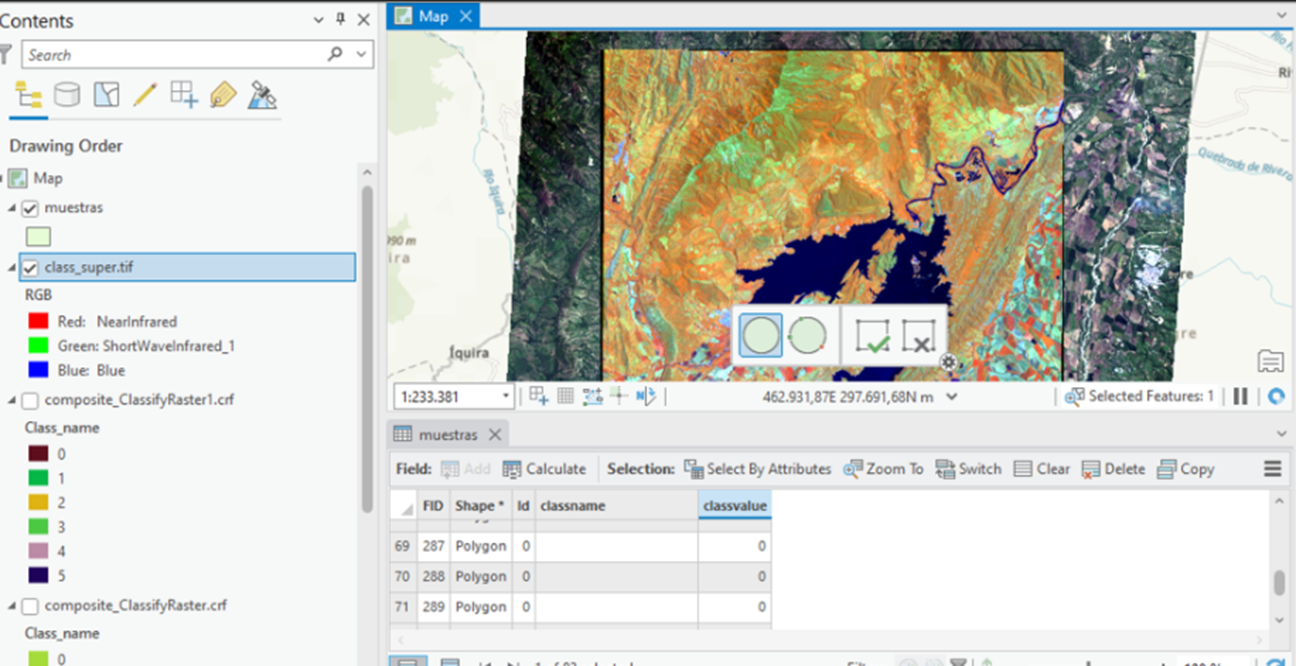
13. Tomando muestras…
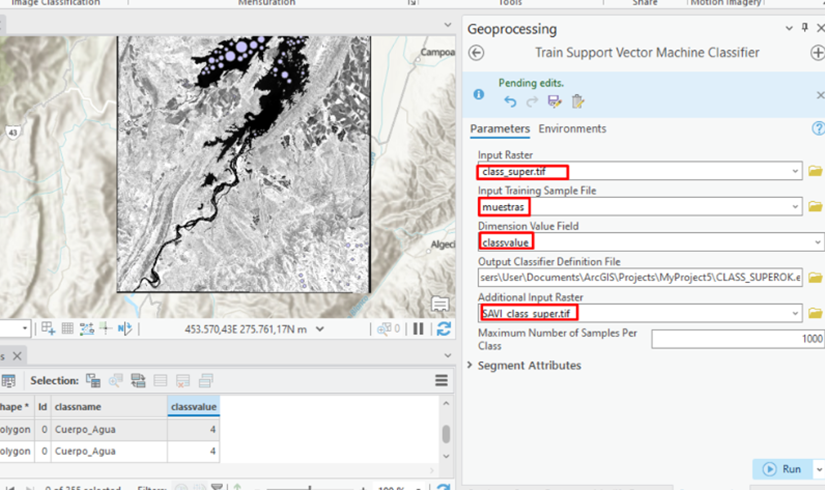
14.Teniendo todas las muestras listas, emplear la herramienta Train Support vector machine classifier.
En el input raster-> el archivo.tif corregido (reflectancia aparente).
Input training sample file-> las muestras.shp
Dimensión value Field -> la columna del classname
Additional Input Raster -> se puede emplear un índice para mejorar la clasificación, en este caso fue el SAVI.
15.Antes de continuar, se requiere realizar nuevamente un archivo shp, que contengan mucho más muestras de las que se emplearon para realizar la clasificación, una vez se tenga el archivo de referencia, se emplea la herramienta create Accuracy assessment points
En el Input raster o Feature class dato: El archivo referencia.shp
Output accuracy: Se guarda con el nombre de matriz de confusión
Target Field: Ground truth

16. Una vez generada la matriz de confusión, se emplea la herramienta Update Accuracy Assesment Point
Input raster or feature class Data: La clasificación previamente realizada de coberturas
Input Accuracy assesment point: La matriz de confusión
Output: Update o cualquier nombre.

- Para generar la matriz de confusión finalmente se emplea la herramienta Compute confusión matrix
Input accuracy Assment Points: Update
Output confusión matrix: Se guarda la salida.dbf
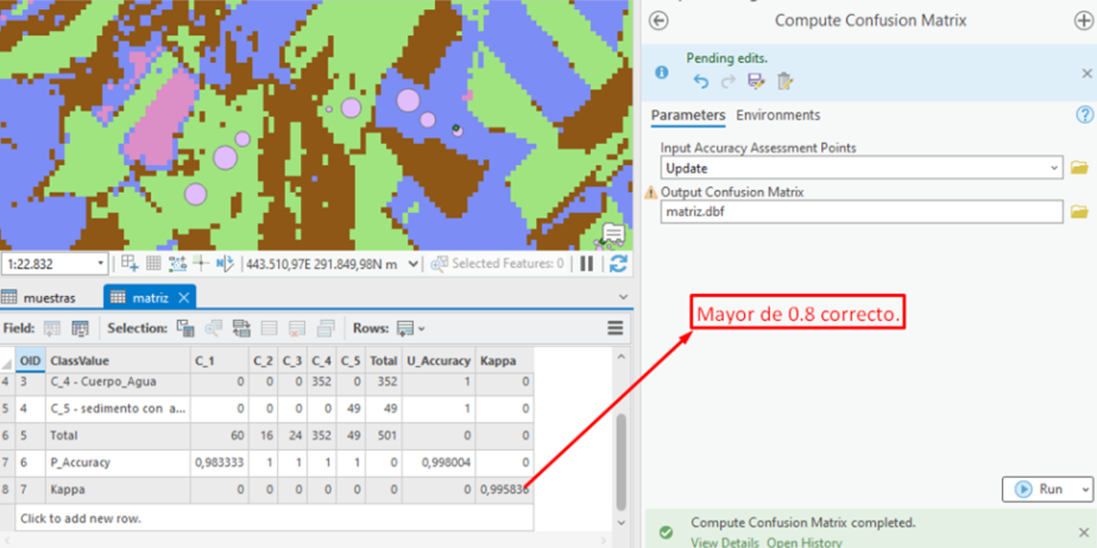
Nota: en este caso el valor de kappa, también conocido como índice Kappa de Cohen, es una medida estadística utilizada para cuantificar el nivel de acuerdo entre dos o más evaluadores que clasifican cada uno los ítems en categorías, genero un valor de 0.9. Por lo general cuando este número es mayor de 0.8 la clasificación ha sido correcta.
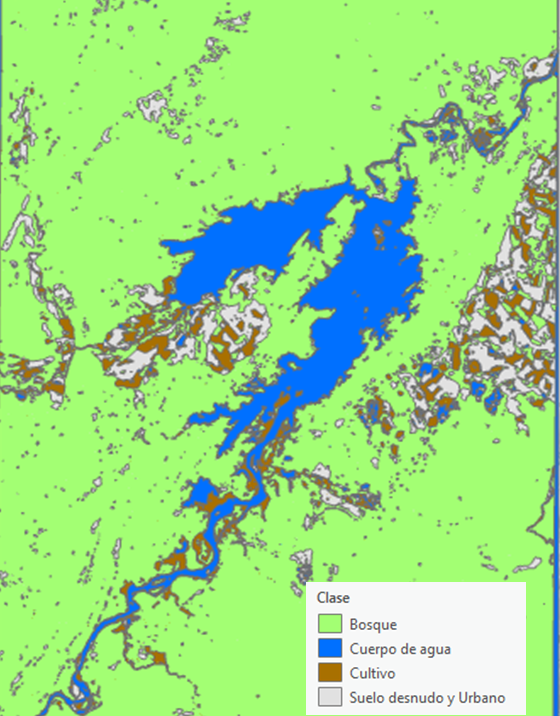
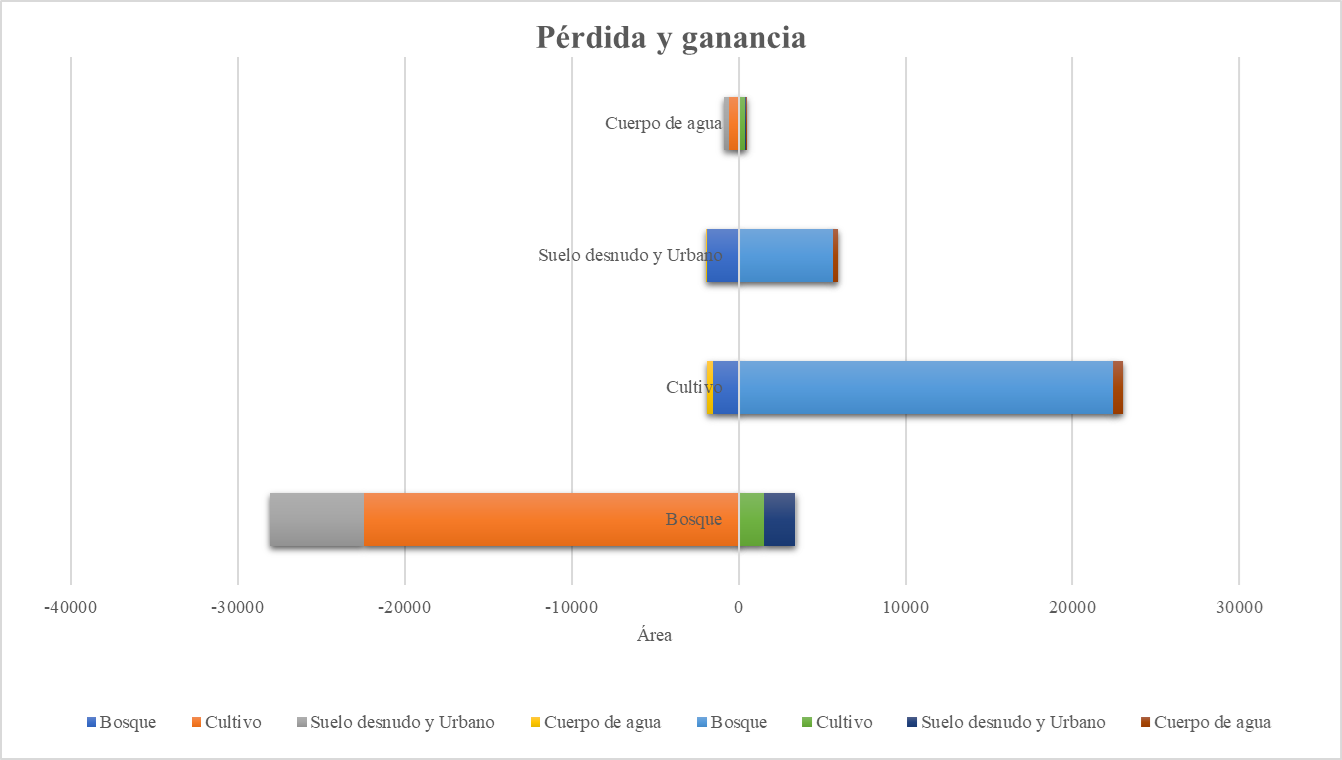
Ahora bien, este mismo procedimiento se realizó con una imagen del 2003, permitiendo hacer un gráfico de pérdidas y ganancias de coberturas entre año 2003 y 2024.
En próximos artículos, te enseñaré a cómo realizar una clasificación en menos pasos…